Common Statistical Methods
In this section, the most commonly used statistical methods from Combine will be covered, including specific instructions on how to obtain limits, significances, and likelihood scans. For all of these methods, the assumed parameter of interest (POI) is the overall signal strength \(r\) (i.e the default PhysicsModel). In general however, the first POI in the list of POIs (as defined by the PhysicsModel) will be taken instead of r. This may or may not make sense for any particular method, so care must be taken.
This section will assume that you are using the default physics model, unless otherwise specified.
Asymptotic Frequentist Limits
The AsymptoticLimits method can be used to quickly compute an estimate of the observed and expected limits, which is accurate when the event yields are not too small and the systematic uncertainties do not play a major role in the result.
The limit calculation relies on an asymptotic approximation of the distributions of the LHC test statistic, which is based on a profile likelihood ratio, under the signal and background hypotheses to compute two p-values \(p_{\mu}, p_{b}\) and therefore \(CL_s=p_{\mu}/(1-p_{b})\) (see the FAQ section for a description). This means it is the asymptotic approximation for evaluating limits with frequentist toys using the LHC test statistic for limits. In the definition below, the parameter \(\mu=r\).
- The test statistic is defined using the ratio of likelihoods \(q_{\mu} = -2\ln[\mathcal{L}(\mu,\hat{\hat{\nu}}(\mu))/\mathcal{L}(\hat{\mu},\hat{\nu})]\) , in which the nuisance parameters are profiled separately for \(\mu=\hat{\mu}\) and \(\mu\). The value of \(q_{\mu}\) is set to 0 when \(\hat{\mu}>\mu\), giving a one-sided limit. Furthermore, the constraint \(\mu>0\) is enforced in the fit. This means that if the unconstrained value of \(\hat{\mu}\) would be negative, the test statistic \(q_{\mu}\) is evaluated as \(-2\ln[\mathcal{L}(\mu,\hat{\hat{\nu}}(\mu))/\mathcal{L}(0,\hat{\hat{\nu}}(0))]\)
This method is the default Combine method: if you call Combine without specifying -M, the AsymptoticLimits method will be run.
A realistic example of a datacard for a counting experiment can be found in the HiggsCombination package: data/tutorials/counting/realistic-counting-experiment.txt
The AsymptoticLimits method can be run using
combine -M AsymptoticLimits realistic-counting-experiment.txt
The program will print the limit on the signal strength r (number of signal events / number of expected signal events) e .g. Observed Limit: r < 1.6297 @ 95% CL , the median expected limit Expected 50.0%: r < 2.3111, and edges of the 68% and 95% ranges for the expected limits.
<<< Combine >>>
>>> including systematics
>>> method used to compute upper limit is AsymptoticLimits
[...]
-- AsymptoticLimits ( CLs ) --
Observed Limit: r < 1.6281
Expected 2.5%: r < 0.9640
Expected 16.0%: r < 1.4329
Expected 50.0%: r < 2.3281
Expected 84.0%: r < 3.9800
Expected 97.5%: r < 6.6194
Done in 0.01 min (cpu), 0.01 min (real)
By default, the limits are calculated using the CLs prescription, as noted in the output, which takes the ratio of p-values under the signal plus background and background only hypothesis. This can be altered to using the strict p-value by using the option --rule CLsplusb (note that CLsplusb is the jargon for calculating the p-value \(p_{\mu}\)). You can also change the confidence level (default is 95%) to 90% using the option --cl 0.9 or any other confidence level. You can find the full list of options for AsymptoticLimits using --help -M AsymptoticLimits.
Warning
You may find that Combine issues a warning that the best fit for the background-only Asimov dataset returns a nonzero value for the signal strength;
WARNING: Best fit of asimov dataset is at r = 0.220944 (0.011047 times rMax), while it should be at zero
If this happens, you should check to make sure that there are no issues with the datacard or the Asimov generation used for your setup. For details on debugging, it is recommended that you follow the simple checks used by the HIG PAG here.
The program will also create a ROOT file higgsCombineTest.AsymptoticLimits.mH120.root containing a ROOT tree limit that contains the limit values and other bookkeeping information. The important columns are limit (the limit value) and quantileExpected (-1 for observed limit, 0.5 for median expected limit, 0.16/0.84 for the edges of the 65% interval band of expected limits, 0.025/0.975 for 95%).
$ root -l higgsCombineTest.AsymptoticLimits.mH120.root
root [0] limit->Scan("*")
************************************************************************************************************************************
* Row * limit * limitErr * mh * syst * iToy * iSeed * iChannel * t_cpu * t_real * quantileE *
************************************************************************************************************************************
* 0 * 0.9639892 * 0 * 120 * 1 * 0 * 123456 * 0 * 0 * 0 * 0.0250000 *
* 1 * 1.4329109 * 0 * 120 * 1 * 0 * 123456 * 0 * 0 * 0 * 0.1599999 *
* 2 * 2.328125 * 0 * 120 * 1 * 0 * 123456 * 0 * 0 * 0 * 0.5 *
* 3 * 3.9799661 * 0 * 120 * 1 * 0 * 123456 * 0 * 0 * 0 * 0.8399999 *
* 4 * 6.6194028 * 0 * 120 * 1 * 0 * 123456 * 0 * 0 * 0 * 0.9750000 *
* 5 * 1.6281188 * 0.0050568 * 120 * 1 * 0 * 123456 * 0 * 0.0035000 * 0.0055123 * -1 *
************************************************************************************************************************************
Blind limits
The AsymptoticLimits calculation follows the frequentist paradigm for calculating expected limits. This means that the routine will first fit the observed data, conditionally for a fixed value of r, and set the nuisance parameters to the values obtained in the fit for generating the Asimov data set. This means it calculates the post-fit or a-posteriori expected limit. In order to use the pre-fit nuisance parameters (to calculate an a-priori limit), you must add the option --noFitAsimov or --bypassFrequentistFit.
For blinding the results completely (i.e not using the data) you can include the option --run blind.
Warning
While you can use -t -1 to get blind limits, if the correct options are passed, we strongly recommend to use --run blind.
Splitting points
In case your model is particularly complex, you can perform the asymptotic calculation by determining the value of CLs for a set grid of points (in r) and merging the results. This is done by using the option --singlePoint X for multiple values of X, hadd'ing the output files and reading them back in,
combine -M AsymptoticLimits realistic-counting-experiment.txt --singlePoint 0.1 -n 0.1
combine -M AsymptoticLimits realistic-counting-experiment.txt --singlePoint 0.2 -n 0.2
combine -M AsymptoticLimits realistic-counting-experiment.txt --singlePoint 0.3 -n 0.3
...
hadd limits.root higgsCombine*.AsymptoticLimits.*
combine -M AsymptoticLimits realistic-counting-experiment.txt --getLimitFromGrid limits.root
Asymptotic Significances
The significance of a result is calculated using a ratio of profiled likelihoods, one in which the signal strength is set to 0 and the other in which it is free to float. The evaluated quantity is \(-2\ln[\mathcal{L}(\mu=0,\hat{\hat{\nu}}(0))/\mathcal{L}(\hat{\mu},\hat{\nu})]\), in which the nuisance parameters are profiled separately for \(\mu=\hat{\mu}\) and \(\mu=0\).
The distribution of this test statistic can be determined using Wilks' theorem provided the number of events is large enough (i.e in the Asymptotic limit). The significance (or p-value) can therefore be calculated very quickly. The Significance method can be used for this.
It is also possible to calculate the ratio of likelihoods between the freely floating signal strength to that of a fixed signal strength other than 0, by specifying it with the option --signalForSignificance=X.
Info
This calculation assumes that the signal strength can only be positive (i.e we are not interested in negative signal strengths). This behaviour can be altered by including the option --uncapped.
Compute the observed significance
The observed significance is calculated using the Significance method, as
combine -M Significance datacard.txt
The printed output will report the significance and the p-value, for example, when using the realistic-counting-experiment.txt datacard, you will see
<<< Combine >>>
>>> including systematics
>>> method used is Significance
[...]
-- Significance --
Significance: 0
(p-value = 0.5)
Done in 0.00 min (cpu), 0.01 min (real)
which is not surprising since 0 events were observed in that datacard.
The output ROOT file will contain the significance value in the branch limit. To store the p-value instead, include the option --pval. The significance and p-value can be converted between one another using the RooFit functions RooFit::PValueToSignificance and RooFit::SignificanceToPValue.
When calculating the significance, you may find it useful to resort to a brute-force fitting algorithm that scans the nll (repeating fits until a certain tolerance is reached), bypassing MINOS, which can be activated with the option bruteForce. This can be tuned using the options setBruteForceAlgo, setBruteForceTypeAndAlgo and setBruteForceTolerance.
Computing the expected significance
The expected significance can be computed from an Asimov data set of signal+background. There are two options for this:
- a-posteriori expected: will depend on the observed dataset.
- a-priori expected (the default behavior): does not depend on the observed dataset, and so is a good metric for optimizing an analysis when still blinded.
The a-priori expected significance from the Asimov dataset is calculated as
combine -M Significance datacard.txt -t -1 --expectSignal=1
In order to produce the a-posteriori expected significance, just generate a post-fit Asimov data set by adding the option --toysFreq in the command above.
The output format is the same as for observed significances: the variable limit in the tree will be filled with the significance (or with the p-value if you put also the option --pvalue)
Bayesian Limits and Credible regions
Bayesian calculation of limits requires the user to assume a particular prior distribution for the parameter of interest (default r). You can specify the prior using the --prior option, the default is a flat pior in r.
Computing the observed bayesian limit (for simple models)
The BayesianSimple method computes a Bayesian limit performing classical numerical integration. This is very fast and accurate, but only works for simple models (a few channels and nuisance parameters).
combine -M BayesianSimple simple-counting-experiment.txt
[...]
-- BayesianSimple --
Limit: r < 0.672292 @ 95% CL
Done in 0.04 min (cpu), 0.05 min (real)
The output tree will contain a single entry corresponding to the observed 95% confidence level upper limit. The confidence level can be modified to 100*X% using --cl X.
Computing the observed bayesian limit (for arbitrary models)
The MarkovChainMC method computes a Bayesian limit performing a Monte Carlo integration. From the statistical point of view it is identical to the BayesianSimple method, only the technical implementation is different. The method is slower, but can also handle complex models. For this method you can increase the accuracy of the result by increasing the number of Markov Chains, at the expense of a longer running time (option --tries, default is 10). Let's use the realistic counting experiment datacard to test the method.
To use the MarkovChainMC method, users need to specify this method in the command line, together with the options they want to use. For instance, to set the number of times the algorithm will run with different random seeds, use option --tries:
combine -M MarkovChainMC realistic-counting-experiment.txt --tries 100
[...]
-- MarkovChainMC --
Limit: r < 2.20438 +/- 0.0144695 @ 95% CL (100 tries)
Average chain acceptance: 0.078118
Done in 0.14 min (cpu), 0.15 min (real)
Again, the resulting limit tree will contain the result. You can also save the chains using the option --saveChain, which will then also be included in the output file.
Exclusion regions can be made from the posterior once an ordering principle is defined to decide how to grow the contour (there is an infinite number of possible regions that contain 68% of the posterior pdf). Below is a simple example script that can be used to plot the posterior distribution from these chains and calculate the smallest such region. Note that in this example we are ignoring the burn-in. This can be added by e.g. changing for i in range(mychain.numEntries()): to for i in range(200,mychain.numEntries()): for a burn-in of 200.
Show example script
import ROOT
rmin = 0
rmax = 30
nbins = 100
CL = 0.95
chains = "higgsCombineTest.MarkovChainMC.blahblahblah.root"
def findSmallestInterval(hist,CL):
bins = hist.GetNbinsX()
best_i = 1
best_j = 1
bd = bins+1
val = 0;
for i in range(1,bins+1):
integral = hist.GetBinContent(i)
for j in range(i+1,bins+2):
integral += hist.GetBinContent(j)
if integral > CL :
val = integral
break
if integral > CL and j-i < bd :
bd = j-i
best_j = j+1
best_i = i
val = integral
return hist.GetBinLowEdge(best_i), hist.GetBinLowEdge(best_j), val
fi_MCMC = ROOT.TFile.Open(chains)
# Sum up all of the chains (or we could take the average limit)
mychain=0
for k in fi_MCMC.Get("toys").GetListOfKeys():
obj = k.ReadObj
if mychain ==0:
mychain = k.ReadObj().GetAsDataSet()
else :
mychain.append(k.ReadObj().GetAsDataSet())
hist = ROOT.TH1F("h_post",";r;posterior probability",nbins,rmin,rmax)
for i in range(mychain.numEntries()):
#for i in range(200,mychain.numEntries()): burn-in of 200
mychain.get(i)
hist.Fill(mychain.get(i).getRealValue("r"), mychain.weight())
hist.Scale(1./hist.Integral())
hist.SetLineColor(1)
vl,vu,trueCL = findSmallestInterval(hist,CL)
histCL = hist.Clone()
for b in range(nbins):
if histCL.GetBinLowEdge(b+1) < vl or histCL.GetBinLowEdge(b+2)>vu: histCL.SetBinContent(b+1,0)
c6a = ROOT.TCanvas()
histCL.SetFillColor(ROOT.kAzure-3)
histCL.SetFillStyle(1001)
hist.Draw()
histCL.Draw("histFsame")
hist.Draw("histsame")
ll = ROOT.TLine(vl,0,vl,2*hist.GetBinContent(hist.FindBin(vl))); ll.SetLineColor(2); ll.SetLineWidth(2)
lu = ROOT.TLine(vu,0,vu,2*hist.GetBinContent(hist.FindBin(vu))); lu.SetLineColor(2); lu.SetLineWidth(2)
ll.Draw()
lu.Draw()
print " %g %% (%g %%) interval (target) = %g < r < %g "%(trueCL,CL,vl,vu)
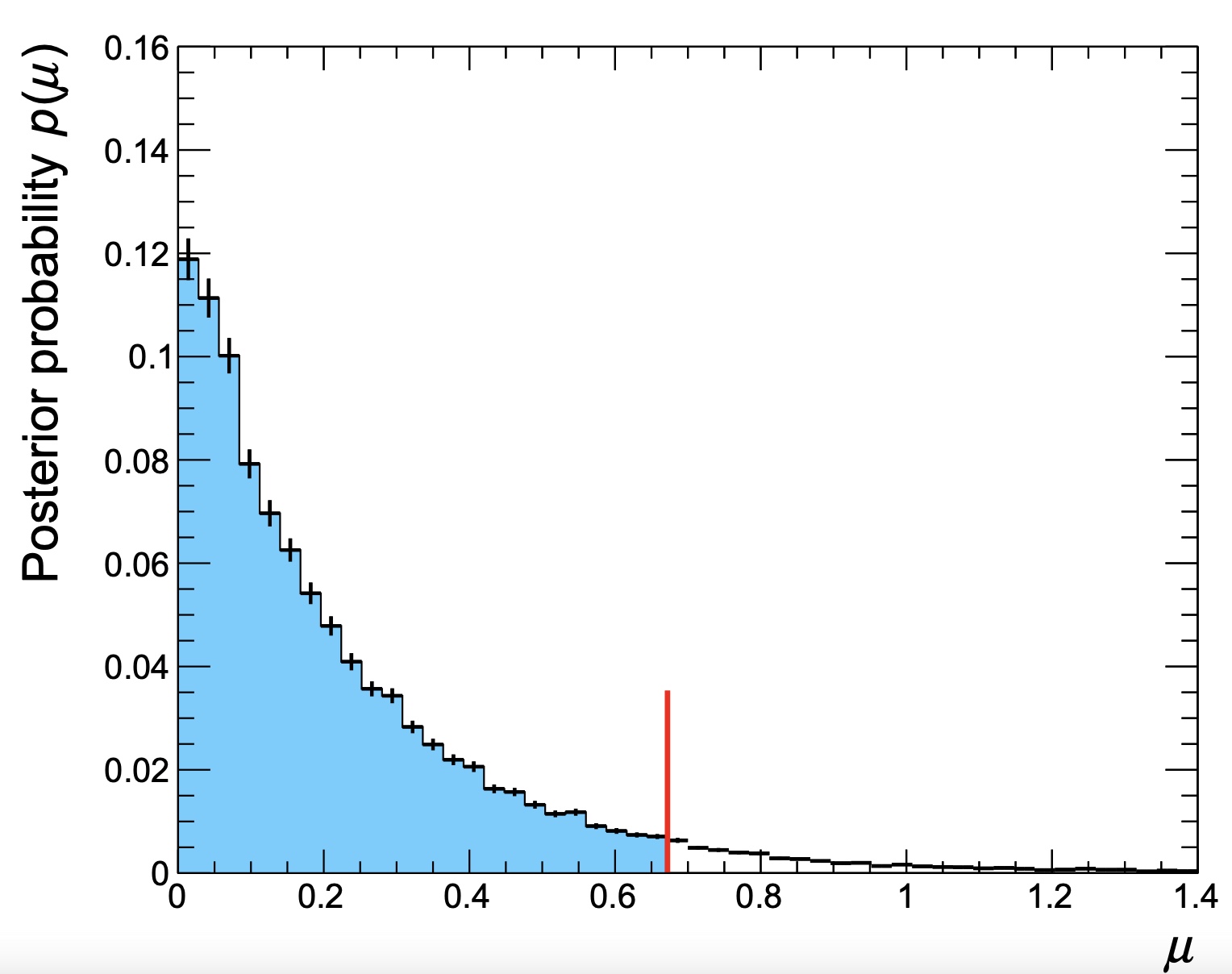
Running the script on the output file produced for the same datacard (including the --saveChain option) will produce the following output
0.950975 % (0.95 %) interval (target) = 0 < r < 2.2
along with a plot of the posterior distribution shown below. This is the same as the output from Combine, but the script can also be used to find lower limits (for example) or credible intervals.
An example to make contours when ordering by probability density can be found in bayesContours.cxx. Note that the implementation is simplistic, with no clever handling of bin sizes nor smoothing of statistical fluctuations.
The MarkovChainMC algorithm has many configurable parameters, and you are encouraged to experiment with those. The default configuration might not be the best for your analysis.
Iterations, burn-in, tries
Three parameters control how the MCMC integration is performed:
- the number of tries (option
--tries): the algorithm will run multiple times with different random seeds. The truncated mean and RMS of the different results are reported. The default value is 10, which should be sufficient for a quick computation. For a more accurate result you might want to increase this number up to even ~200. - the number of iterations (option
-i) determines how many points are proposed to fill a single Markov Chain. The default value is 10k, and a plausible range is between 5k (for quick checks) and 20-30k for lengthy calculations. Beyond 30k, the time vs accuracy can be balanced better by increasing the number of chains (option--tries). - the number of burn-in steps (option
-b) is the number of points that are removed from the beginning of the chain before using it to compute the limit. The default is 200. If the chain is very long, we recommend to increase this value a bit (e.g. to several hundreds). Using a number of burn-in steps below 50 is likely to result in a bias towards earlier stages of the chain before a reasonable convergence.
Proposals
The option --proposal controls the way new points are proposed to fill in the MC chain.
- uniform: pick points at random. This works well if you have very few nuisance parameters (or none at all), but normally fails if you have many.
- gaus: Use a product of independent gaussians, one for each nuisance parameter. The sigma of the gaussian for each variable is 1/5 of the range of the variable. This behaviour can be controlled using the parameter
--propHelperWidthRangeDivisor. This proposal appears to work well for up to around 15 nuisance parameters, provided that the range of the nuisance parameters is in the range ±5σ. This method does not work when there are no nuisance parameters. - ortho (default): This proposal is similar to the multi-gaussian proposal. However, at every step only a single coordinate of the point is varied, so that the acceptance of the chain is high even for a large number of nuisance parameters (i.e. more than 20).
- fit: Run a fit and use the uncertainty matrix from HESSE to construct a proposal (or the one from MINOS if the option
--runMinosis specified). This can give biased results, so this method is not recommended in general.
If you believe there is something going wrong, e.g. if your chain remains stuck after accepting only a few events, the option --debugProposal can be used to obtain a printout of the first N proposed points. This can help you understand what is happening; for example if you have a region of the phase space with probability zero, the gaus and fit proposal can get stuck there forever.
Computing the expected bayesian limit
The expected limit is computed by generating many toy MC data sets and computing the limit for each of them. This can be done passing the option -t . E.g. to run 100 toys with the BayesianSimple method, you can run
combine -M BayesianSimple datacard.txt -t 100
The program will print out the mean and median limit, as well as the 68% and 95% quantiles of the distributions of the limits. This time, the output ROOT tree will contain one entry per toy.
For more heavy methods (eg the MarkovChainMC) you will probably want to split this calculation into multiple jobs. To do this, just run Combine multiple times specifying a smaller number of toys (as low as 1), using a different seed to initialize the random number generator each time. The option -s can be used for this; if you set it to -1, the starting seed will be initialized randomly at the beginning of the job. Finally, you can merge the resulting trees with hadd and look at the distribution in the merged file.
Multidimensional bayesian credible regions
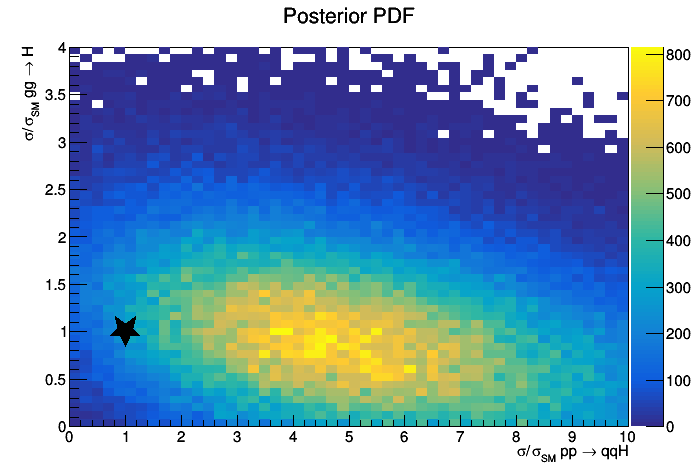
The MarkovChainMC method allows the user to produce the posterior PDF as a function of (in principle) any number of POIs. In order to do so, you first need to create a workspace with more than one parameter, as explained in the physics models section.
For example, let us use the toy datacard data/tutorials/multiDim/toy-hgg-125.txt (counting experiment that vaguely resembles an early H→γγ analysis at 125 GeV) and convert the datacard into a workspace with 2 parameters, the ggH and qqH cross sections, using text2workspace.
text2workspace.py data/tutorials/multiDim/toy-hgg-125.txt -P HiggsAnalysis.CombinedLimit.PhysicsModel:floatingXSHiggs --PO modes=ggH,qqH -o workspace.root
Now we just run one (or more) MCMC chain(s) and save them in the output tree. By default, the nuisance parameters will be marginalized (integrated) over their PDFs. You can ignore the complaints about not being able to compute an upper limit (since for more than 1D, this is not well-defined),
combine -M MarkovChainMC workspace.root --tries 1 --saveChain -i 1000000 -m 125 -s 12345
The output of the Markov Chain is again a RooDataSet of weighted events distributed according to the posterior PDF (after you cut out the burn in part), so it can be used to make histograms or other distributions of the posterior PDF. See as an example bayesPosterior2D.cxx.
Below is an example of the output of the macro,
$ root -l higgsCombineTest.MarkovChainMC....
.L bayesPosterior2D.cxx
bayesPosterior2D("bayes2D","Posterior PDF")
Computing Limits with toys
The HybridNew method is used to compute either the hybrid bayesian-frequentist limits, popularly known as "CLs of LEP or Tevatron type", or the fully frequentist limits, which are the current recommended method by the LHC Higgs Combination Group. Note that these methods can be resource intensive for complex models.
It is possible to define the criterion used for setting limits using --rule CLs (to use the CLs criterion) or --rule CLsplusb (to calculate the limit using \(p_{\mu}\)) and as always the confidence level desired using --cl=X.
The choice of test statistic can be made via the option --testStat. Different methodologies for the treatment of the nuisance parameters are available. While it is possible to mix different test statistics with different nuisance parameter treatments, we strongly do not recommend this. Instead one should follow one of the following three procedures. Note that the signal strength \(r\) here is given the more common notation \(\mu\).
-
LEP-style:
--testStat LEP --generateNuisances=1 --fitNuisances=0- The test statistic is defined using the ratio of likelihoods \(q_{\mathrm{LEP}}=-2\ln[\mathcal{L}(\mu=0)/\mathcal{L}(\mu)]\).
- The nuisance parameters are fixed to their nominal values for the purpose of evaluating the likelihood, while for generating toys, the nuisance parameters are first randomized within their PDFs before generation of the toy.
-
TEV-style:
--testStat TEV --generateNuisances=0 --generateExternalMeasurements=1 --fitNuisances=1- The test statistic is defined using the ratio of likelihoods \(q_{\mathrm{TEV}}=-2\ln[\mathcal{L}(\mu=0,\hat{\hat{\mu}}(0))/\mathcal{L}(\mu,\hat{\hat{\nu}}(\mu))]\), in which the nuisance parameters are profiled separately for \(\mu=0\) and \(\mu\).
- For the purposes of toy generation, the nuisance parameters are fixed to their post-fit values from the data (conditional on \(\mu\)), while the constraint terms are randomized for the evaluation of the likelihood.
-
LHC-style:
--LHCmode LHC-limits, which is the shortcut for--testStat LHC --generateNuisances=0 --generateExternalMeasurements=1 --fitNuisances=1- The test statistic is defined using the ratio of likelihoods \(q_{\mu} = -2\ln[\mathcal{L}(\mu,\hat{\hat{\nu}}(\mu))/\mathcal{L}(\hat{\mu},\hat{\nu})]\) , in which the nuisance parameters are profiled separately for \(mu=\hat{\mu}\) and \(\mu\).
- The value of \(q_{\mu}\) set to 0 when \(\hat{\mu}>\mu\) giving a one-sided limit. Furthermore, the constraint \(\mu>0\) is enforced in the fit. This means that if the unconstrained value of \(\hat{\mu}\) would be negative, the test statistic \(q_{\mu}\) is evaluated as \(-2\ln[\mathcal{L}(\mu,\hat{\hat{\nu}}(\mu))/\mathcal{L}(0,\hat{\hat{\nu}}(0))]\).
- For the purposes of toy generation, the nuisance parameters are fixed to their post-fit values from the data (conditionally on the value of \(\mu\)), while the constraint terms are randomized in the evaluation of the likelihood.
Warning
The recommended style is the LHC-style. Please note that this method is sensitive to the observation in data since the post-fit (after a fit to the data) values of the nuisance parameters (assuming different values of r) are used when generating the toys. For completely blind limits you can first generate a pre-fit asimov toy data set (described in the toy data generation section) and use that in place of the data. You can use this toy by passing the argument -D toysFileName.root:toys/toy_asimov
While the above shortcuts are the commonly used versions, variations can be tested. The treatment of the nuisances can be changed to the so-called "Hybrid-Bayesian" method, which effectively integrates over the nuisance parameters. This is especially relevant when you have very few expected events in your data, and you are using those events to constrain background processes. This can be achieved by setting --generateNuisances=1 --generateExternalMeasurements=0. In case you want to avoid first fitting to the data to choose the nominal values you can additionally pass --fitNuisances=0.
Warning
If you have unconstrained parameters in your model (rateParam, or if you are using a _norm variable for a PDF) and you want to use the "Hybrid-Bayesian" method, you must declare these as flatParam in your datacard. When running text2workspace you must add the option --X-assign-flatParam-prior in the command line. This will create uniform priors for these parameters. These are needed for this method and they would otherwise not get created.
Info
Note that (observed and expected) values of the test statistic stored in the instances of RooStats::HypoTestResult when the option --saveHybridResult is passed are defined without the factor 2. They are therefore twice as small as the values given by the formulas above. This factor is however included automatically by all plotting scripts supplied within the Combine package. If you use your own plotting scripts, you need to make sure to incorporate the factor 2.
Simple models
For relatively simple models, the observed and expected limits can be calculated interactively. Since the LHC-style is the recommended set of options for calculating limits using toys, we will use that in this section. However, the same procedure can be followed with the other sets of options.
combine realistic-counting-experiment.txt -M HybridNew --LHCmode LHC-limits
Show output
<<< Combine >>>
>>> including systematics
>>> using the Profile Likelihood test statistics modified for upper limits (Q_LHC)
>>> method used is HybridNew
>>> random number generator seed is 123456
Computing results starting from observation (a-posteriori)
Search for upper limit to the limit
r = 20 +/- 0
CLs = 0 +/- 0
CLs = 0 +/- 0
CLb = 0.264 +/- 0.0394263
CLsplusb = 0 +/- 0
Search for lower limit to the limit
Now doing proper bracketing & bisection
r = 10 +/- 10
CLs = 0 +/- 0
CLs = 0 +/- 0
CLb = 0.288 +/- 0.0405024
CLsplusb = 0 +/- 0
r = 5 +/- 5
CLs = 0 +/- 0
CLs = 0 +/- 0
CLb = 0.152 +/- 0.0321118
CLsplusb = 0 +/- 0
r = 2.5 +/- 2.5
CLs = 0.0192308 +/- 0.0139799
CLs = 0.02008 +/- 0.0103371
CLs = 0.0271712 +/- 0.00999051
CLs = 0.0239524 +/- 0.00783634
CLs = 0.0239524 +/- 0.00783634
CLb = 0.208748 +/- 0.0181211
CLsplusb = 0.005 +/- 0.00157718
r = 2.00696 +/- 1.25
CLs = 0.0740741 +/- 0.0288829
CLs = 0.0730182 +/- 0.0200897
CLs = 0.0694474 +/- 0.0166468
CLs = 0.0640182 +/- 0.0131693
CLs = 0.0595 +/- 0.010864
CLs = 0.0650862 +/- 0.0105575
CLs = 0.0629286 +/- 0.00966301
CLs = 0.0634945 +/- 0.00914091
CLs = 0.060914 +/- 0.00852667
CLs = 0.06295 +/- 0.00830083
CLs = 0.0612758 +/- 0.00778181
CLs = 0.0608142 +/- 0.00747001
CLs = 0.0587169 +/- 0.00697039
CLs = 0.0591432 +/- 0.00678587
CLs = 0.0599683 +/- 0.00666966
CLs = 0.0574868 +/- 0.00630809
CLs = 0.0571451 +/- 0.00608177
CLs = 0.0553836 +/- 0.00585531
CLs = 0.0531612 +/- 0.0055234
CLs = 0.0516837 +/- 0.0052607
CLs = 0.0496776 +/- 0.00499783
CLs = 0.0496776 +/- 0.00499783
CLb = 0.216635 +/- 0.00801002
CLsplusb = 0.0107619 +/- 0.00100693
Trying to move the interval edges closer
r = 1.00348 +/- 0
CLs = 0.191176 +/- 0.0459911
CLs = 0.191176 +/- 0.0459911
CLb = 0.272 +/- 0.0398011
CLsplusb = 0.052 +/- 0.00992935
r = 1.50522 +/- 0
CLs = 0.125 +/- 0.0444346
CLs = 0.09538 +/- 0.0248075
CLs = 0.107714 +/- 0.0226712
CLs = 0.103711 +/- 0.018789
CLs = 0.0845069 +/- 0.0142341
CLs = 0.0828468 +/- 0.0126789
CLs = 0.0879647 +/- 0.0122332
CLs = 0.0879647 +/- 0.0122332
CLb = 0.211124 +/- 0.0137494
CLsplusb = 0.0185714 +/- 0.00228201
r = 1.75609 +/- 0
CLs = 0.0703125 +/- 0.0255807
CLs = 0.0595593 +/- 0.0171995
CLs = 0.0555271 +/- 0.0137075
CLs = 0.0548727 +/- 0.0120557
CLs = 0.0527832 +/- 0.0103348
CLs = 0.0555828 +/- 0.00998248
CLs = 0.0567971 +/- 0.00923449
CLs = 0.0581822 +/- 0.00871417
CLs = 0.0588835 +/- 0.00836245
CLs = 0.0594035 +/- 0.00784761
CLs = 0.0590583 +/- 0.00752672
CLs = 0.0552067 +/- 0.00695542
CLs = 0.0560446 +/- 0.00679746
CLs = 0.0548083 +/- 0.0064351
CLs = 0.0566998 +/- 0.00627124
CLs = 0.0561576 +/- 0.00601888
CLs = 0.0551643 +/- 0.00576338
CLs = 0.0583584 +/- 0.00582854
CLs = 0.0585691 +/- 0.0057078
CLs = 0.0599114 +/- 0.00564585
CLs = 0.061987 +/- 0.00566905
CLs = 0.061836 +/- 0.00549856
CLs = 0.0616849 +/- 0.0053773
CLs = 0.0605352 +/- 0.00516844
CLs = 0.0602028 +/- 0.00502875
CLs = 0.058667 +/- 0.00486263
CLs = 0.058667 +/- 0.00486263
CLb = 0.222901 +/- 0.00727258
CLsplusb = 0.0130769 +/- 0.000996375
r = 2.25348 +/- 0
CLs = 0.0192308 +/- 0.0139799
CLs = 0.0173103 +/- 0.00886481
CLs = 0.0173103 +/- 0.00886481
CLb = 0.231076 +/- 0.0266062
CLsplusb = 0.004 +/- 0.001996
r = 2.13022 +/- 0
CLs = 0.0441176 +/- 0.0190309
CLs = 0.0557778 +/- 0.01736
CLs = 0.0496461 +/- 0.0132776
CLs = 0.0479048 +/- 0.0114407
CLs = 0.0419333 +/- 0.00925719
CLs = 0.0367934 +/- 0.0077345
CLs = 0.0339814 +/- 0.00684844
CLs = 0.03438 +/- 0.0064704
CLs = 0.0337633 +/- 0.00597315
CLs = 0.0321262 +/- 0.00551608
CLs = 0.0321262 +/- 0.00551608
CLb = 0.230342 +/- 0.0118665
CLsplusb = 0.0074 +/- 0.00121204
r = 2.06859 +/- 0
CLs = 0.0357143 +/- 0.0217521
CLs = 0.0381957 +/- 0.0152597
CLs = 0.0368622 +/- 0.0117105
CLs = 0.0415097 +/- 0.0106676
CLs = 0.0442816 +/- 0.0100457
CLs = 0.0376644 +/- 0.00847235
CLs = 0.0395133 +/- 0.0080427
CLs = 0.0377625 +/- 0.00727262
CLs = 0.0364415 +/- 0.00667827
CLs = 0.0368015 +/- 0.00628517
CLs = 0.0357251 +/- 0.00586442
CLs = 0.0341604 +/- 0.00546373
CLs = 0.0361935 +/- 0.00549648
CLs = 0.0403254 +/- 0.00565172
CLs = 0.0408613 +/- 0.00554124
CLs = 0.0416682 +/- 0.00539651
CLs = 0.0432645 +/- 0.00538062
CLs = 0.0435229 +/- 0.00516945
CLs = 0.0427647 +/- 0.00501322
CLs = 0.0414894 +/- 0.00479711
CLs = 0.0414894 +/- 0.00479711
CLb = 0.202461 +/- 0.00800632
CLsplusb = 0.0084 +/- 0.000912658
-- HybridNew, before fit --
Limit: r < 2.00696 +/- 1.25 [1.50522, 2.13022]
Warning in : Could not create the Migrad minimizer. Try using the minimizer Minuit
Fit to 5 points: 1.91034 +/- 0.0388334
-- Hybrid New --
Limit: r < 1.91034 +/- 0.0388334 @ 95% CL
Done in 0.01 min (cpu), 4.09 min (real)
Failed to delete temporary file roostats-Sprxsw.root: No such file or directory
The result stored in the limit branch of the output tree will be the upper limit (and its error, stored in limitErr). The default behaviour will be, as above, to search for the upper limit on r. However, the values of \(p_{\mu}, p_{b}\) and CLs can be calculated for a particular value r=X by specifying the option --singlePoint=X. In this case, the value stored in the branch limit will be the value of CLs (or \(p_{\mu}\)) (see the FAQ section).
Expected Limits
For simple models, we can run interactively 5 times to compute the median expected and the 68% and 95% central interval boundaries. For this, we can use the HybridNew method with the same options as for the observed limit, but adding a --expectedFromGrid=<quantile>. Here, the quantile should be set to 0.5 for the median, 0.84 for the +ve side of the 68% band, 0.16 for the -ve side of the 68% band, 0.975 for the +ve side of the 95% band, and 0.025 for the -ve side of the 95% band.
The output file will contain the value of the quantile in the branch quantileExpected. This branch can therefore be used to separate the points.
Accuracy
The search for the limit is performed using an adaptive algorithm, terminating when the estimate of the limit value is below some limit or when the precision cannot be improved further with the specified options. The options controlling this behaviour are:
rAbsAcc,rRelAcc: define the accuracy on the limit at which the search stops. The default values are 0.1 and 0.05 respectively, meaning that the search is stopped when Δr < 0.1 or Δr/r < 0.05.clsAcc: this determines the absolute accuracy up to which the CLs values are computed when searching for the limit. The default is 0.5%. Raising the accuracy above this value will significantly increase the time needed to run the algorithm, as you need N2 more toys to improve the accuracy by a factor N. You can consider increasing this value if you are computing limits with a larger CL (e.g. 90% or 68%). Note that if you are using theCLsplusbrule, this parameter will control the uncertainty on \(p_{\mu}\) rather than CLs.TortoysH: controls the minimum number of toys that are generated for each point. The default value of 500 should be sufficient when computing the limit at 90-95% CL. You can decrease this number if you are computing limits at 68% CL, or increase it if you are using 99% CL.
Note, to further improve the accuracy when searching for the upper limit, Combine will also fit an exponential function to several of the points and interpolate to find the crossing.
Complex models
For complicated models, it is best to produce a grid of test statistic distributions at various values of the signal strength, and use it to compute the observed and expected limit and central intervals. This approach is convenient for complex models, since the grid of points can be distributed across any number of jobs. In this approach we will store the distributions of the test statistic at different values of the signal strength using the option --saveHybridResult. The distribution at a single value of r=X can be determined by
combine datacard.txt -M HybridNew --LHCmode LHC-limits --singlePoint X --saveToys --saveHybridResult -T 500 --clsAcc 0
Warning
We have specified the accuracy here by including --clsAcc=0, which turns off adaptive sampling, and specifying the number of toys to be 500 with the -T N option. For complex models, it may be necessary to internally split the toys over a number of instances of HybridNew using the option --iterations I. The total number of toys will be the product I*N.
The above can be repeated several times, in parallel, to build the distribution of the test statistic (passing the random seed option -s -1). Once all of the distributions have been calculated, the resulting output files can be merged into one using hadd, and read back to calculate the limit, specifying the merged file with --grid=merged.root.
The observed limit can be obtained with
combine datacard.txt -M HybridNew --LHCmode LHC-limits --readHybridResults --grid=merged.root
and similarly, the median expected and quantiles can be determined using
combine datacard.txt -M HybridNew --LHCmode LHC-limits --readHybridResults --grid=merged.root --expectedFromGrid <quantile>
substituting <quantile> with 0.5 for the median, 0.84 for the +ve side of the 68% band, 0.16 for the -ve side of the 68% band, 0.975 for the +ve side of the 95% band, and 0.025 for the -ve side of the 95% band. You should note that Combine will update the grid to improve the accuracy on the extracted limit by default. If you want to avoid this, you can use the option --noUpdateGrid. This will mean only the toys/points you produced in the grid will be used to compute the limit.
Warning
Make sure that if you specified a particular mass value (-m or --mass) in the commands for calculating the toys, you also specify the same mass when reading in the grid of distributions.
The splitting of the jobs can be left to the user's preference. However, users may wish to use the combineTool for automating this, as described in the section on combineTool for job submission
Plotting
A plot of the CLs (or \(p_{\mu}\)) as a function of r, which is used to find the crossing, can be produced using the option --plot=limit_scan.png. This can be useful for judging if the chosen grid was sufficient for determining the upper limit.
If we use our realistic-counting-experiment.txt datacard and generate a grid of points \(r\varepsilon[1.4,2.2]\) in steps of 0.1, with 5000 toys for each point, the plot of the observed CLs vs r should look like the following,
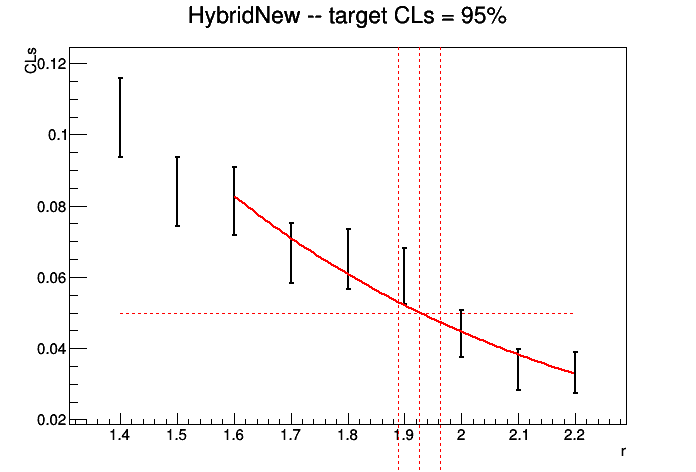
You should judge in each case whether the limit is accurate given the spacing of the points and the precision of CLs at each point. If it is not sufficient, simply generate more points closer to the limit and/or more toys at each point.
The distributions of the test statistic can also be plotted, at each value in the grid, using
python test/plotTestStatCLs.py --input mygrid.root --poi r --val all --mass MASS
The resulting output file will contain a canvas showing the distribution of the test statistics for the background only and signal+background hypotheses at each value of r. Use --help to see more options for this script.
Info
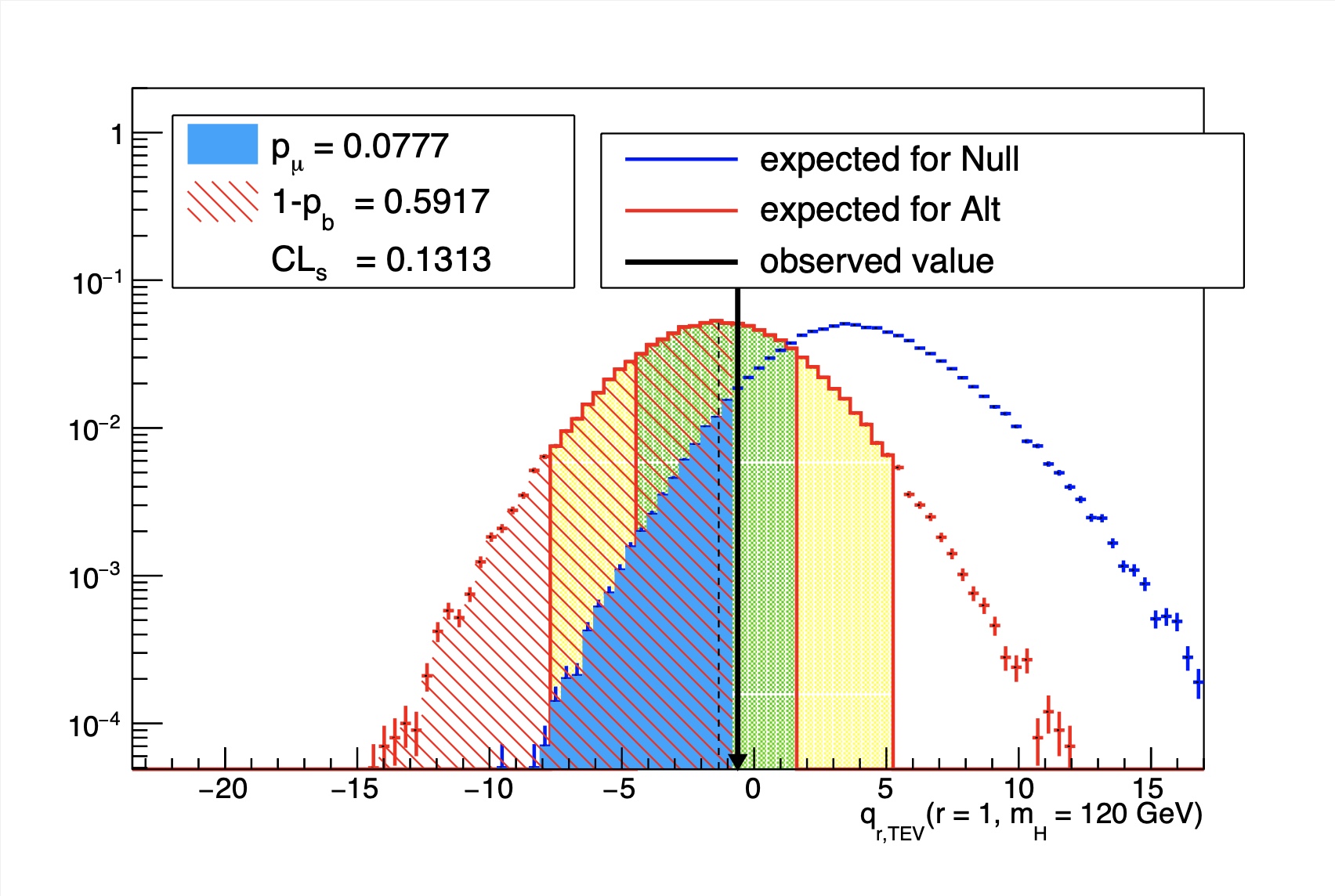
If you used the TEV or LEP style test statistic (using the commands as described above), then you should include the option --doublesided, which will also take care of defining the correct integrals for \(p_{\mu}\) and \(p_{b}\). Click on the examples below to see what a typical output of this plotting tool will look like when using the LHC test statistic, or the TEV test statistic.
qLHC test stat example
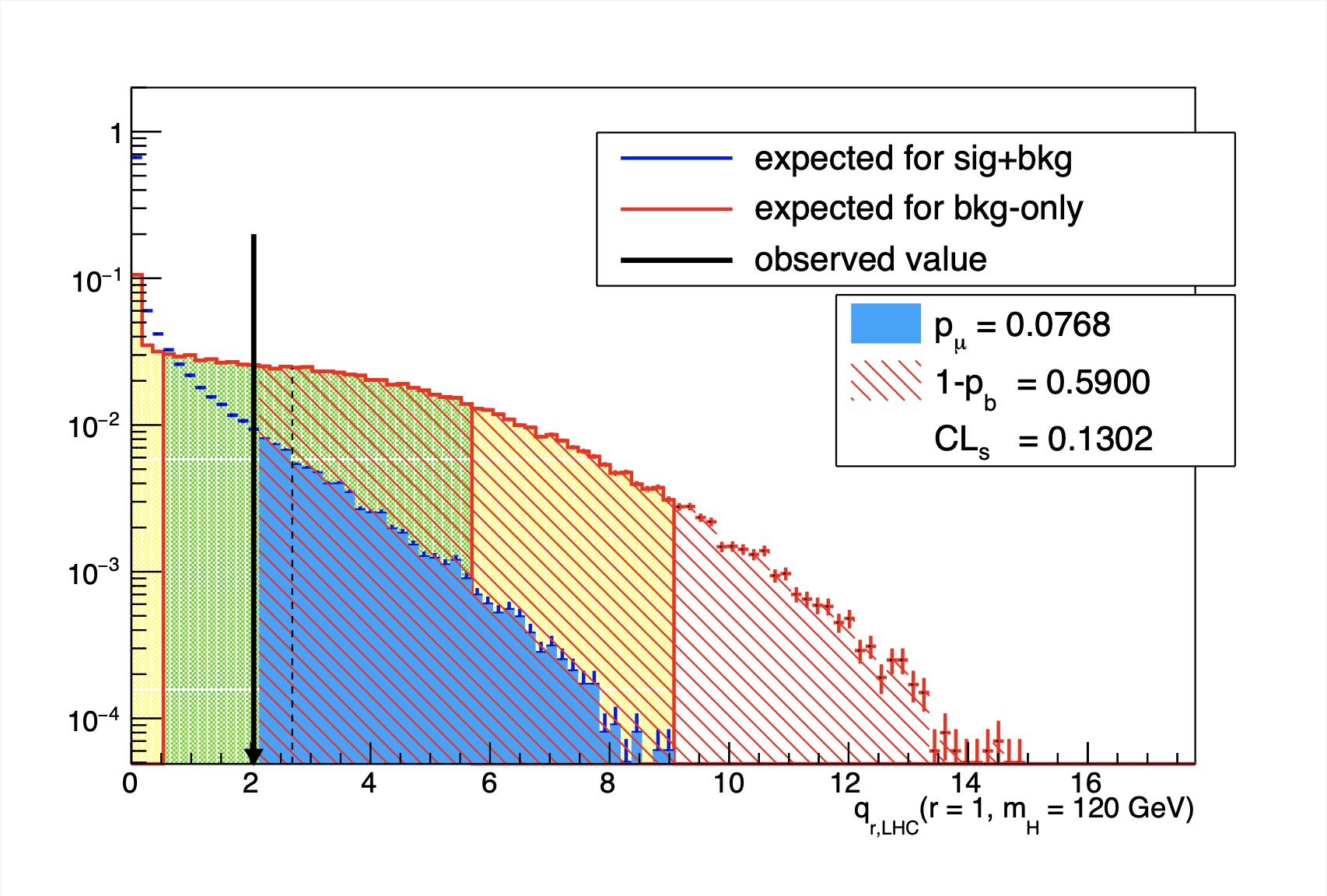
qTEV test stat example
Computing Significances with toys
Computation of the expected significance with toys is a two-step procedure: first you need to run one or more jobs to construct the expected distribution of the test statistic. As for setting limits, there are a number of different possible configurations for generating toys. However, we will use the most commonly used option,
- LHC-style:
--LHCmode LHC-significance, which is the shortcut for--testStat LHC --generateNuisances=0 --generateExternalMeasurements=1 --fitNuisances=1 --significance- The test statistic is defined using the ratio of likelihoods \(q_{0} = -2\ln[\mathcal{L}(\mu=0,\hat{\hat{\nu}}(0))/\mathcal{L}(\hat{\mu},\hat{\nu})]\), in which the nuisance parameters are profiled separately for \(\mu=\hat{\mu}\) and \(\mu=0\).
- The value of the test statistic is set to 0 when \(\hat{\mu}<0\)
- For the purposes of toy generation, the nuisance parameters are fixed to their post-fit values from the data assuming no signal, while the constraint terms are randomized for the evaluation of the likelihood.
Observed significance
To construct the distribution of the test statistic, the following command should be run as many times as necessary
combine -M HybridNew datacard.txt --LHCmode LHC-significance --saveToys --fullBToys --saveHybridResult -T toys -i iterations -s seed
with different seeds, or using -s -1 for random seeds, then merge all those results into a single ROOT file with hadd. The toys can then be read back into combine using the option --toysFile=input.root --readHybridResult.
The observed significance can be calculated as
combine -M HybridNew datacard.txt --LHCmode LHC-significance --readHybridResult --toysFile=input.root [--pvalue ]
where the option --pvalue will replace the result stored in the limit branch output tree to be the p-value instead of the signficance.
Expected significance, assuming some signal
The expected significance, assuming a signal with r=X can be calculated, by including the option --expectSignal X when generating the distribution of the test statistic and using the option --expectedFromGrid=0.5 when calculating the significance for the median. To get the ±1σ bands, use 0.16 and 0.84 instead of 0.5, and so on.
The total number of background toys needs to be large enough to compute the value of the significance, but you need fewer signal toys (especially when you are only computing the median expected significance). For large significances, you can run most of the toys without the --fullBToys option, which will be about a factor 2 faster. Only a small part of the toys needs to be run with that option turned on.
As with calculating limits with toys, these jobs can be submitted to the grid or batch systems with the help of the combineTool, as described in the section on combineTool for job submission
Goodness of fit tests
The GoodnessOfFit method can be used to evaluate how compatible the observed data are with the model PDF.
This method implements several algorithms, and will compute a goodness of fit indicator for the chosen algorithm and the data. The procedure is therefore to first run on the real data
combine -M GoodnessOfFit datacard.txt --algo=<some-algo>
and then to run on many toy MC data sets to determine the distribution of the goodness-of-fit indicator
combine -M GoodnessOfFit datacard.txt --algo=<some-algo> -t <number-of-toys> -s <seed>
When computing the goodness-of-fit, by default the signal strength is left floating in the fit, so that the measure is independent from the presence or absence of a signal. It is possible to fixe the signal strength to some value by passing the option --fixedSignalStrength=<value>.
The following algorithms are implemented:
-
saturated: Compute a goodness-of-fit measure for binned fits based on the saturated model, as prescribed by the Statistics Committee (note). This quantity is similar to a chi-square, but can be computed for an arbitrary combination of binned channels with arbitrary constraints. -
KS: Compute a goodness-of-fit measure for binned fits using the Kolmogorov-Smirnov test. It is based on the largest difference between the cumulative distribution function and the empirical distribution function of any bin. -
AD: Compute a goodness-of-fit measure for binned fits using the Anderson-Darling test. It is based on the integral of the difference between the cumulative distribution function and the empirical distribution function over all bins. It also gives the tail ends of the distribution a higher weighting.
The output tree will contain a branch called limit, which contains the value of the test statistic in each toy. You can make a histogram of this test statistic \(t\). From the distribution that is obtained in this way (\(f(t)\)) and the single value obtained by running on the observed data (\(t_{0}\)) you can calculate the p-value \(p = \int_{t=t_{0}}^{\mathrm{+inf}} f(t) dt\). Note: in rare cases the test statistic value for the toys can be undefined (for AS and KD). In this case we set the test statistic value to -1. When plotting the test statistic distribution, those toys should be excluded. This is automatically taken care of if you use the GoF collection script in CombineHarvester, which is described below.
When generating toys, the default behavior will be used. See the section on toy generation for options that control how nuisance parameters are generated and fitted in these tests. It is recommended to use frequentist toys (--toysFreq) when running the saturated model, and the default toys for the other two tests.
Further goodness-of-fit methods could be added on request, especially if volunteers are available to code them. The output limit tree will contain the value of the test statistic in each toy (or the data)
Warning
The above algorithms are all concerned with one-sample tests. For two-sample tests, you can follow an example CMS HIN analysis described in this Twiki
Masking analysis regions in the saturated model
For analyses that employ a simultaneous fit across signal and control regions, it may be useful to mask one or more analysis regions, either when the likelihood is maximized (fit) or when the test statistic is computed. This can be done by using the options --setParametersForFit and --setParametersForEval, respectively. The former will set parameters before each fit, while the latter is used to set parameters after each fit, but before the NLL is evaluated. Note, of course, that if the parameter in the list is floating, it will still be floating in each fit. Therefore, it will not affect the results when using --setParametersForFit.
A realistic example for a binned shape analysis performed in one signal region and two control samples can be found in this directory of the Combine package Datacards-shape-analysis-multiple-regions.
First of all, one needs to Combine the individual datacards to build a single model, and to introduce the channel masking variables as follow:
combineCards.py signal_region.txt dimuon_control_region.txt singlemuon_control_region.txt > combined_card.txt
text2workspace.py combined_card.txt --channel-masks
More information about the channel masking can be found in this section Channel Masking. The saturated test static value for a simultaneous fit across all the analysis regions can be calculated as:
combine -M GoodnessOfFit -d combined_card.root --algo=saturated -n _result_sb
In this case, signal and control regions are included in both the fit and in the evaluation of the test statistic, and the signal strength is freely floating. This measures the compatibility between the signal+background fit and the observed data. Moreover, it can be interesting to assess the level of compatibility between the observed data in all the regions and the background prediction obtained by only fitting the control regions (CR-only fit). This can be evaluated as follow:
combine -M GoodnessOfFit -d combined_card.root --algo=saturated -n _result_bonly_CRonly --setParametersForFit mask_ch1=1 --setParametersForEval mask_ch1=0 --freezeParameters r --setParameters r=0
where the signal strength is frozen and the signal region is not considered in the fit (--setParametersForFit mask_ch1=1), but it is included in the test statistic computation (--setParametersForEval mask_ch1=0). To show the differences between the two models being tested, one can perform a fit to the data using the FitDiagnostics method as:
combine -M FitDiagnostics -d combined_card.root -n _fit_result --saveShapes --saveWithUncertainties
combine -M FitDiagnostics -d combined_card.root -n _fit_CRonly_result --saveShapes --saveWithUncertainties --setParameters mask_ch1=1
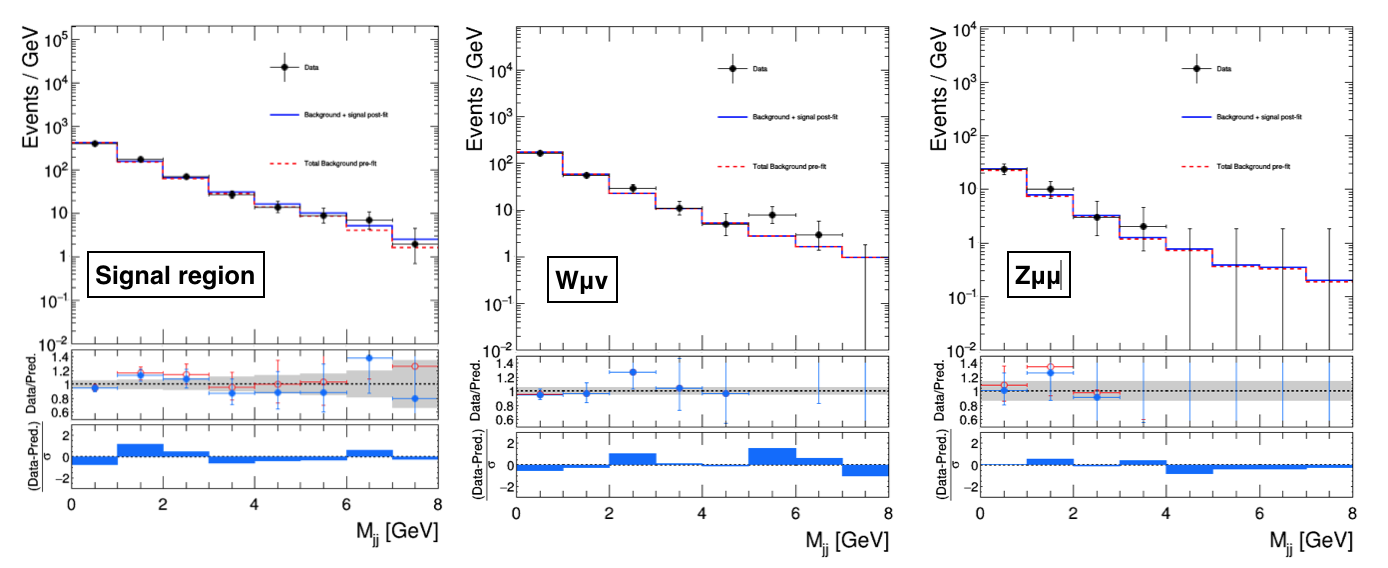
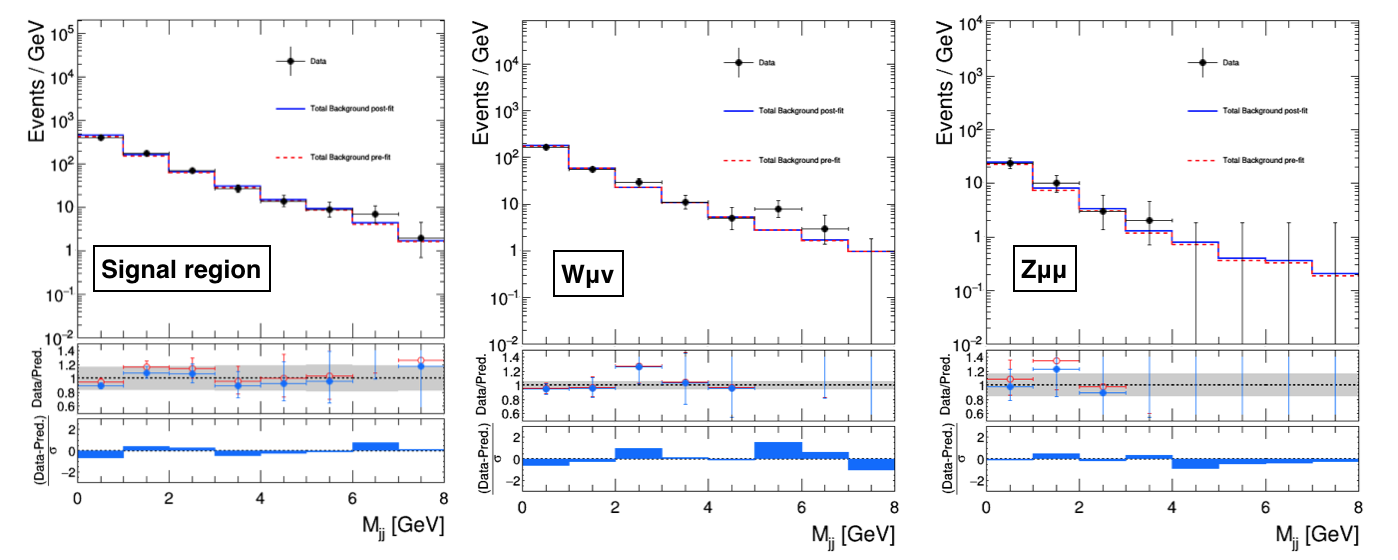
By taking the total background, the total signal, and the data shapes from the FitDiagnostics output, we can compare the post-fit predictions from the S+B fit (first case) and the CR-only fit (second case) with the observation as reported below:
FitDiagnostics S+B fit
FitDiagnostics CR-only fit
To compute a p-value for the two results, one needs to compare the observed goodness-of-fit value previously computed with the expected distribution of the test statistic obtained in toys:
combine -M GoodnessOfFit combined_card.root --algo=saturated -n result_toy_sb --toysFrequentist -t 500
combine -M GoodnessOfFit -d combined_card.root --algo=saturated -n _result_bonly_CRonly_toy --setParametersForFit mask_ch1=1 --setParametersForEval mask_ch1=0 --freezeParameters r --setParameters r=0,mask_ch1=1 -t 500 --toysFrequentist
where the former gives the result for the S+B model, while the latter gives the test-statistic for CR-only fit. The command --setParameters r=0,mask_ch1=1 is needed to ensure that toys are thrown using the nuisance parameters estimated from the CR-only fit to the data. The comparison between the observation and the expected distribition should look like the following two plots:
Goodness-of-fit for S+B model
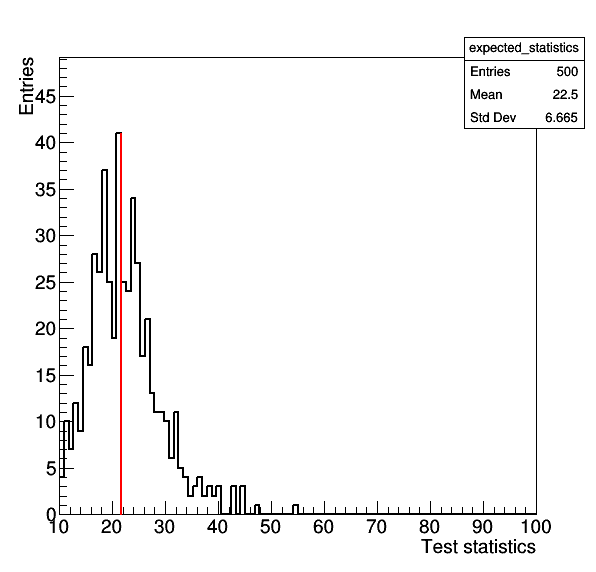
Goodness-of-fit for CR-only model
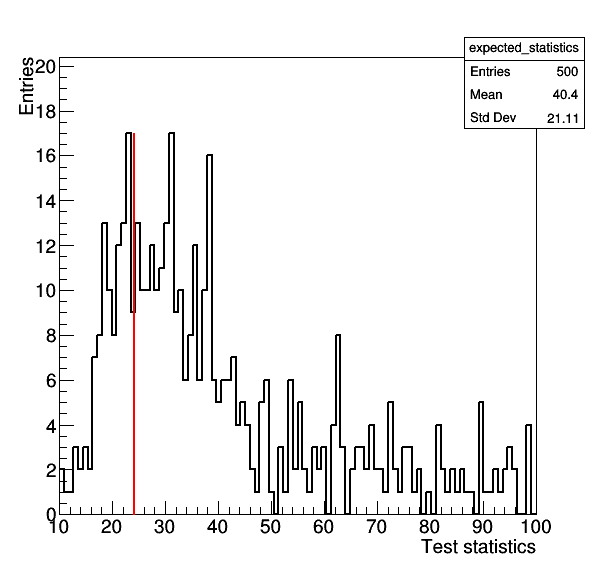
Making a plot of the GoF test statistic distribution
If you have also checked out the combineTool, you can use this to run batch jobs or on the grid (see here) and produce a plot of the results. Once the jobs have completed, you can hadd them together and run (e.g for the saturated model),
combineTool.py -M CollectGoodnessOfFit --input data_run.root toys_run.root -m 125.0 -o gof.json
plotGof.py gof.json --statistic saturated --mass 125.0 -o gof_plot --title-right="my label"
Channel Compatibility
The ChannelCompatibilityCheck method can be used to evaluate how compatible the measurements of the signal strength from the separate channels of a combination are with each other.
The method performs two fits of the data, first with the nominal model in which all channels are assumed to have the same signal strength modifier \(r\), and then another allowing separate signal strengths \(r_{i}\) in each channel. A chisquare-like quantity is computed as \(-2 \ln \mathcal{L}(\mathrm{data}| r)/L(\mathrm{data}|\{r_{i}\}_{i=1}^{N_{\mathrm{chan}}})\). Just like for the goodness-of-fit indicators, the expected distribution of this quantity under the nominal model can be computed from toy MC data sets.
By default, the signal strength is kept floating in the fit with the nominal model. It can however be fixed to a given value by passing the option --fixedSignalStrength=<value>.
In the default model built from the datacards, the signal strengths in all channels are constrained to be non-negative. One can allow negative signal strengths in the fits by changing the bound on the variable (option --rMin=<value>), which should make the quantity more chisquare-like under the hypothesis of zero signal; this however can create issues in channels with small backgrounds, since total expected yields and PDFs in each channel must be positive.
Optionally, channels can be grouped together by using the option -g <name_fragment>, where <name_fragment> is a string which is common to all channels to be grouped together. The -g option can also be used to set the range for the each POI separately via -g <name>=<min>,<max>.
When run with a verbosity of 1, as is the default, the program also prints out the best fit signal strengths in all channels. As the fit to all channels is done simultaneously, the correlation between the other systematic uncertainties is taken into account. Therefore, these results can differ from the ones obtained when fitting each channel separately.
Below is an example output from Combine,
$ combine -M ChannelCompatibilityCheck comb_hww.txt -m 160 -n HWW
<<< Combine >>>
>>> including systematics
>>> method used to compute upper limit is ChannelCompatibilityCheck
>>> random number generator seed is 123456
Sanity checks on the model: OK
Computing limit starting from observation
--- ChannelCompatibilityCheck ---
Nominal fit : r = 0.3431 -0.1408/+0.1636
Alternate fit: r = 0.4010 -0.2173/+0.2724 in channel hww_0jsf_shape
Alternate fit: r = 0.2359 -0.1854/+0.2297 in channel hww_0jof_shape
Alternate fit: r = 0.7669 -0.4105/+0.5380 in channel hww_1jsf_shape
Alternate fit: r = 0.3170 -0.3121/+0.3837 in channel hww_1jof_shape
Alternate fit: r = 0.0000 -0.0000/+0.5129 in channel hww_2j_cut
Chi2-like compatibility variable: 2.16098
Done in 0.08 min (cpu), 0.08 min (real)
The output tree will contain the value of the compatibility (chi-square variable) in the limit branch. If the option --saveFitResult is specified, the output ROOT file also contains two RooFitResult objects fit_nominal and fit_alternate with the results of the two fits.
This can be read and used to extract the best fit value for each channel, and the overall best fit value, using
$ root -l
TFile* _file0 = TFile::Open("higgsCombineTest.ChannelCompatibilityCheck.mH120.root");
fit_alternate->floatParsFinal().selectByName("*ChannelCompatibilityCheck*")->Print("v");
fit_nominal->floatParsFinal().selectByName("r")->Print("v");
The macro cccPlot.cxx can be used to produce a comparison plot of the best fit signal strengths from all channels.
Likelihood Fits and Scans
The MultiDimFit method can be used to perform multi-dimensional fits and likelihood-based scans/contours using models with several parameters of interest.
Taking a toy datacard data/tutorials/multiDim/toy-hgg-125.txt (counting experiment which vaguely resembles an early H→γγ analysis at 125 GeV), we need to convert the datacard into a workspace with 2 parameters, the ggH and qqH cross sections:
text2workspace.py toy-hgg-125.txt -m 125 -P HiggsAnalysis.CombinedLimit.PhysicsModel:floatingXSHiggs --PO modes=ggH,qqH
A number of different algorithms can be used with the option --algo <algo>,
-
none(default): Perform a maximum likelihood fitcombine -M MultiDimFit toy-hgg-125.root; The output ROOT tree will contain two columns, one for each parameter, with the fitted values. -
singles: Perform a fit of each parameter separately, treating the other parameters of interest as unconstrained nuisance parameters:combine -M MultiDimFit toy-hgg-125.root --algo singles --cl=0.68. The output ROOT tree will contain two columns, one for each parameter, with the fitted values; there will be one row with the best fit point (andquantileExpectedset to -1) and two rows for each fitted parameter, where the corresponding column will contain the maximum and minimum of that parameter in the 68% CL interval, according to a one-dimensional chi-square (i.e. uncertainties on each fitted parameter do not increase when adding other parameters if they are uncorrelated). Note that if you run, for example, with--cminDefaultMinimizerStrategy=0, these uncertainties will be derived from the Hessian, while--cminDefaultMinimizerStrategy=1will invoke Minos to derive them. -
cross: Perform a joint fit of all parameters:combine -M MultiDimFit toy-hgg-125.root --algo=cross --cl=0.68. The output ROOT tree will have one row with the best fit point, and two rows for each parameter, corresponding to the minimum and maximum of that parameter on the likelihood contour corresponding to the specified CL, according to an N-dimensional chi-square (i.e. the uncertainties on each fitted parameter do increase when adding other parameters, even if they are uncorrelated). Note that this method does not produce 1D uncertainties on each parameter, and should not be taken as such. -
contour2d: Make a 68% CL contour à la minoscombine -M MultiDimFit toy-hgg-125.root --algo contour2d --points=20 --cl=0.68. The output will contain values corresponding to the best fit point (withquantileExpectedset to -1) and for a set of points on the contour (withquantileExpectedset to 1-CL, or something larger than that if the contour hits the boundary of the parameters). Probabilities are computed from the the n-dimensional \(\chi^{2}\) distribution. For slow models, this method can be split by running several times with a different number of points, and merging the outputs. The contourPlot.cxx macro can be used to make plots out of this algorithm. -
random: Scan N random points and compute the probability out of the profile likelihood ratiocombine -M MultiDimFit toy-hgg-125.root --algo random --points=20 --cl=0.68. Again, the best fit will havequantileExpectedset to -1, while each random point will havequantileExpectedset to the probability given by the profile likelihood ratio at that point. -
fixed: Compare the log-likelihood at a fixed point compared to the best fit.combine -M MultiDimFit toy-hgg-125.root --algo fixed --fixedPointPOIs r=r_fixed,MH=MH_fixed. The output tree will contain the difference in the negative log-likelihood between the points (\(\hat{r},\hat{m}_{H}\)) and (\(\hat{r}_{fixed},\hat{m}_{H,fixed}\)) in the branchdeltaNLL. -
grid: Scan a fixed grid of points with approximately N points in total.combine -M MultiDimFit toy-hgg-125.root --algo grid --points=10000.- You can partition the job in multiple tasks by using the options
--firstPointand--lastPoint. For complicated scans, the points can be split as described in the combineTool for job submission section. The output file will contain a columndeltaNLLwith the difference in negative log-likelihood with respect to the best fit point. Ranges/contours can be evaluated by filling TGraphs or TH2 histograms with these points. - By default the "min" and "max" of the POI ranges are not included and the points that are in the scan are centred , eg
combine -M MultiDimFit --algo grid --rMin 0 --rMax 5 --points 5will scan at the points \(r=0.5, 1.5, 2.5, 3.5, 4.5\). You can include the option--alignEdges 1, which causes the points to be aligned with the end-points of the parameter ranges - e.g.combine -M MultiDimFit --algo grid --rMin 0 --rMax 5 --points 6 --alignEdges 1will scan at the points \(r=0, 1, 2, 3, 4, 5\). Note - the number of points must be increased by 1 to ensure both end points are included.
- You can partition the job in multiple tasks by using the options
With the algorithms none and singles you can save the RooFitResult from the initial fit using the option --saveFitResult. The fit result is saved into a new file called multidimfit.root.
As usual, any floating nuisance parameters will be profiled. This behaviour can be modified by using the --freezeParameters option.
For most of the methods, for lower-precision results you can turn off the profiling of the nuisance parameters by using the option --fastScan, which for complex models speeds up the process by several orders of magnitude. All nuisance parameters will be kept fixed at the value corresponding to the best fit point.
As an example, let's produce the \(-2\Delta\ln{\mathcal{L}}\) scan as a function of r_ggH and r_qqH from the toy H→γγ datacard, with the nuisance parameters fixed to their global best fit values.
combine toy-hgg-125.root -M MultiDimFit --algo grid --points 2000 --setParameterRanges r_qqH=0,10:r_ggH=0,4 -m 125 --fastScan
Show output
<<< Combine >>>
>>> including systematics
>>> method used is MultiDimFit
>>> random number generator seed is 123456
ModelConfig 'ModelConfig' defines more than one parameter of interest. This is not supported in some statistical methods.
Set Range of Parameter r_qqH To : (0,10)
Set Range of Parameter r_ggH To : (0,4)
Computing results starting from observation (a-posteriori)
POI: r_ggH= 0.88152 -> [0,4]
POI: r_qqH= 4.68297 -> [0,10]
Point 0/2025, (i,j) = (0,0), r_ggH = 0.044444, r_qqH = 0.111111
Point 11/2025, (i,j) = (0,11), r_ggH = 0.044444, r_qqH = 2.555556
Point 22/2025, (i,j) = (0,22), r_ggH = 0.044444, r_qqH = 5.000000
Point 33/2025, (i,j) = (0,33), r_ggH = 0.044444, r_qqH = 7.444444
Point 55/2025, (i,j) = (1,10), r_ggH = 0.133333, r_qqH = 2.333333
Point 66/2025, (i,j) = (1,21), r_ggH = 0.133333, r_qqH = 4.777778
Point 77/2025, (i,j) = (1,32), r_ggH = 0.133333, r_qqH = 7.222222
Point 88/2025, (i,j) = (1,43), r_ggH = 0.133333, r_qqH = 9.666667
Point 99/2025, (i,j) = (2,9), r_ggH = 0.222222, r_qqH = 2.111111
Point 110/2025, (i,j) = (2,20), r_ggH = 0.222222, r_qqH = 4.555556
Point 121/2025, (i,j) = (2,31), r_ggH = 0.222222, r_qqH = 7.000000
Point 132/2025, (i,j) = (2,42), r_ggH = 0.222222, r_qqH = 9.444444
Point 143/2025, (i,j) = (3,8), r_ggH = 0.311111, r_qqH = 1.888889
Point 154/2025, (i,j) = (3,19), r_ggH = 0.311111, r_qqH = 4.333333
Point 165/2025, (i,j) = (3,30), r_ggH = 0.311111, r_qqH = 6.777778
Point 176/2025, (i,j) = (3,41), r_ggH = 0.311111, r_qqH = 9.222222
Point 187/2025, (i,j) = (4,7), r_ggH = 0.400000, r_qqH = 1.666667
Point 198/2025, (i,j) = (4,18), r_ggH = 0.400000, r_qqH = 4.111111
Point 209/2025, (i,j) = (4,29), r_ggH = 0.400000, r_qqH = 6.555556
Point 220/2025, (i,j) = (4,40), r_ggH = 0.400000, r_qqH = 9.000000
[...]
Done in 0.00 min (cpu), 0.02 min (real)
The scan, along with the best fit point can be drawn using root,
$ root -l higgsCombineTest.MultiDimFit.mH125.root
limit->Draw("2*deltaNLL:r_ggH:r_qqH>>h(44,0,10,44,0,4)","2*deltaNLL<10","prof colz")
limit->Draw("r_ggH:r_qqH","quantileExpected == -1","P same")
TGraph *best_fit = (TGraph*)gROOT->FindObject("Graph")
best_fit->SetMarkerSize(3); best_fit->SetMarkerStyle(34); best_fit->Draw("p same")
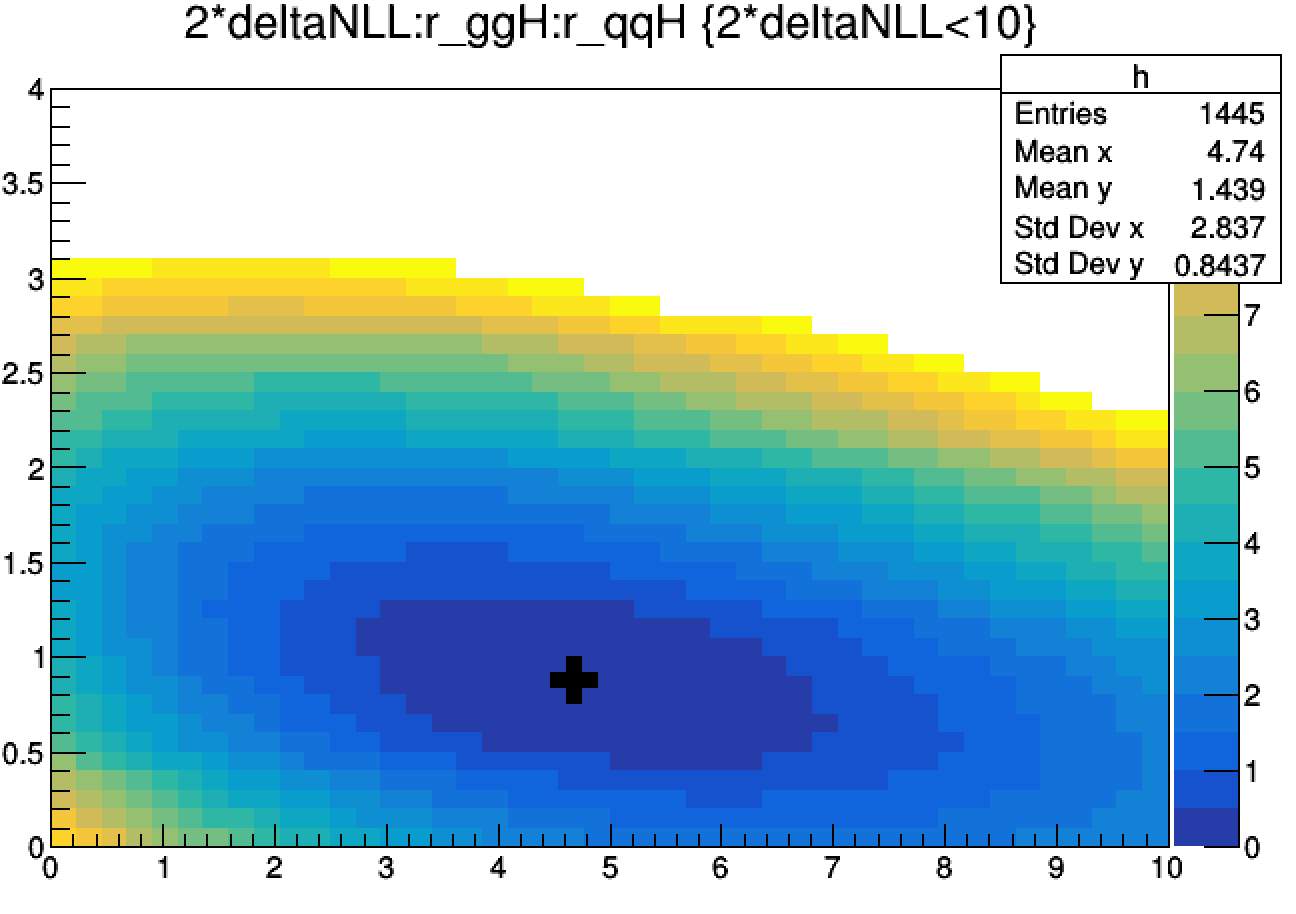
To make the full profiled scan, just remove the --fastScan option from the Combine command.
Similarly, 1D scans can be drawn directly from the tree, however for 1D likelihood scans, there is a python script from the CombineHarvester/CombineTools package plot1DScan.py that can be used to make plots and extract the crossings of the 2*deltaNLL - e.g the 1σ/2σ boundaries.
Useful options for likelihood scans
A number of common, useful options (especially for computing likelihood scans with the grid algo) are,
--autoBoundsPOIs arg: Adjust bounds for the POIs if they end up close to the boundary. This can be a comma-separated list of POIs, or "*" to get all of them.--autoMaxPOIs arg: Adjust maxima for the POIs if they end up close to the boundary. Can be a list of POIs, or "*" to get all.--autoRange X: Set to any X >= 0 to do the scan in the \(\hat{p}\) \(\pm\) Xσ range, where \(\hat{p}\) and σ are the best fit parameter value and uncertainty from the initial fit (so it may be fairly approximate). In case you do not trust the estimate of the error from the initial fit, you can just centre the range on the best fit value by using the option--centeredRange Xto do the scan in the \(\hat{p}\) \(\pm\) X range centered on the best fit value.--squareDistPoiStep: POI step size based on distance from the midpoint ( either (max-min)/2 or the best fit if used with--autoRangeor--centeredRange) rather than linear separation.--skipInitialFit: Skip the initial fit (saves time if, for example, a snapshot is loaded from a previous fit)
Below is a comparison in a likelihood scan, with 20 points, as a function of r_qqH with our toy-hgg-125.root workspace with and without some of these options. The options added tell Combine to scan more points closer to the minimum (best-fit) than with the default.
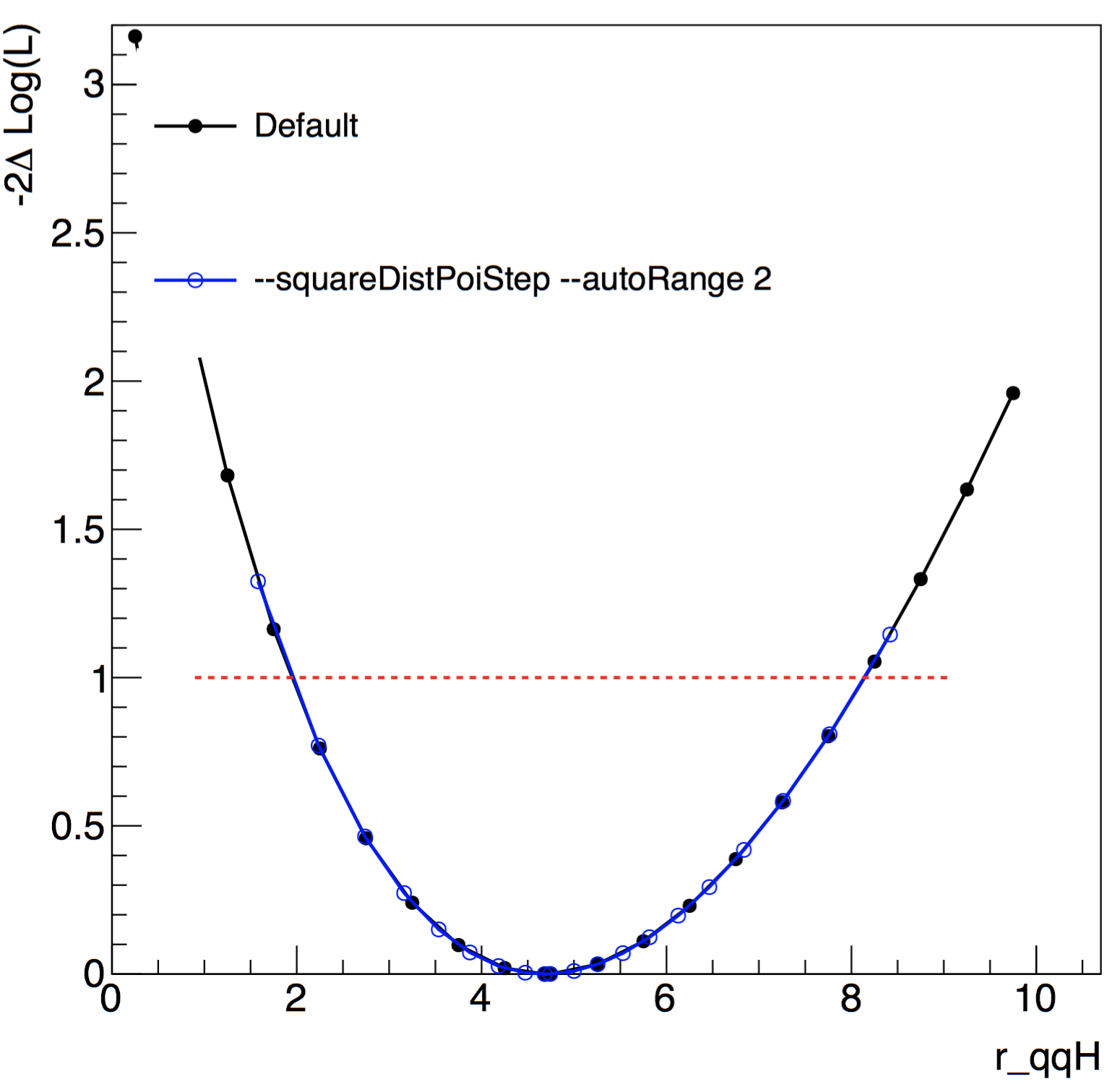
You may find it useful to use the --robustFit=1 option to turn on robust (brute-force) for likelihood scans (and other algorithms). You can set the strategy and tolerance when using the --robustFit option using the options --setRobustFitAlgo (default is Minuit2,migrad), setRobustFitStrategy (default is 0) and --setRobustFitTolerance (default is 0.1). If these options are not set, the defaults (set using cminDefaultMinimizerX options) will be used.
If running --robustFit=1 with the algo singles, you can tune the accuracy of the routine used to find the crossing points of the likelihood using the option --setCrossingTolerance (the default is set to 0.0001)
If you suspect your fits/uncertainties are not stable, you may also try to run custom HESSE-style calculation of the covariance matrix. This is enabled by running MultiDimFit with the --robustHesse=1 option. A simple example of how the default behaviour in a simple datacard is given here.
For a full list of options use combine -M MultiDimFit --help
Fitting only some parameters
If your model contains more than one parameter of interest, you can still decide to fit a smaller number of them, using the option --parameters (or -P), with a syntax like this:
combine -M MultiDimFit [...] -P poi1 -P poi2 ... --floatOtherPOIs=(0|1)
If --floatOtherPOIs is set to 0, the other parameters of interest (POIs), which are not included as a -P option, are kept fixed to their nominal values. If it's set to 1, they are kept floating, which has different consequences depending on algo:
- When running with
--algo=singles, the other floating POIs are treated as unconstrained nuisance parameters. - When running with
--algo=crossor--algo=contour2d, the other floating POIs are treated as other POIs, and so they increase the number of dimensions of the chi-square.
As a result, when running with --floatOtherPOIs set to 1, the uncertainties on each fitted parameters do not depend on the selection of POIs passed to MultiDimFit, but only on the number of parameters of the model.
Info
Note that poi given to the the option -P can also be any nuisance parameter. However, by default, the other nuisance parameters are left floating, so in general this does not need to be specified.
You can save the values of the other parameters of interest in the output tree by passing the option --saveInactivePOI=1. You can additionally save the post-fit values any nuisance parameter, function, or discrete index (RooCategory) defined in the workspace using the following options;
--saveSpecifiedNuis=arg1,arg2,...will store the fitted value of any specified constrained nuisance parameter. Useallto save every constrained nuisance parameter. Note that if you want to store the values offlatParams(or floating parameters that are not defined in the datacard) orrateParams, which are unconstrained, you should instead use the generic option--trackParametersas described here.--saveSpecifiedFunc=arg1,arg2,...will store the value of any function (egRooFormulaVar) in the model.--saveSpecifiedIndex=arg1,arg2,...will store the index of anyRooCategoryobject - eg adiscretenuisance.
Using best fit snapshots
This can be used to save time when performing scans so that the best fit does not need to be repeated. It can also be used to perform scans with some nuisance parameters frozen to their best-fit values. This can be done as follows,
- Create a workspace for a floating \(r,m_{H}\) fit
text2workspace.py hgg_datacard_mva_8TeV_bernsteins.txt -m 125 -P HiggsAnalysis.CombinedLimit.PhysicsModel:floatingHiggsMass --PO higgsMassRange=120,130 -o testmass.root`
- Perfom the fit, saving the workspace
combine -m 123 -M MultiDimFit --saveWorkspace -n teststep1 testmass.root --verbose 9
Now we can load the best fit \(\hat{r},\hat{m}_{H}\) and fit for \(r\) freezing \(m_{H}\) and lumi_8TeV to their best-fit values,
combine -m 123 -M MultiDimFit -d higgsCombineteststep1.MultiDimFit.mH123.root -w w --snapshotName "MultiDimFit" -n teststep2 --verbose 9 --freezeParameters MH,lumi_8TeV
Feldman-Cousins
The Feldman-Cousins (FC) procedure for computing confidence intervals for a generic model is,
- use the profile likelihood ratio as the test statistic, \(q(x) = - 2 \ln \mathcal{L}(x,\hat{\hat{\nu}}(x))/\mathcal{L}(\hat{x},\hat{\nu})\) where \(x\) is a point in the (N-dimensional) parameter space, and \(\hat{x}\) is the point corresponding to the best fit. In this test statistic, the nuisance parameters are profiled, both in the numerator and denominator.
- for each point \(x\):
- compute the observed test statistic \(q_{\mathrm{obs}}(x)\)
- compute the expected distribution of \(q(x)\) under the hypothesis of \(x\) as the true value.
- accept the point in the region if \(p_{x}=P\left[q(x) > q_{\mathrm{obs}}(x)| x\right] > \alpha\)
With a critical value \(\alpha\).
In Combine, you can perform this test on each individual point (param1, param2,...) = (value1,value2,...) by doing,
combine workspace.root -M HybridNew --LHCmode LHC-feldman-cousins --clsAcc 0 --singlePoint param1=value1,param2=value2,param3=value3,... --saveHybridResult [Other options for toys, iterations etc as with limits]
The point belongs to your confidence region if \(p_{x}\) is larger than \(\alpha\) (e.g. 0.3173 for a 1σ region, \(1-\alpha=0.6827\)).
Warning
You should not use this method without the option --singlePoint. Although Combine will not complain, the algorithm to find the crossing will only find a single crossing and therefore not find the correct interval. Instead you should calculate the Feldman-Cousins intervals as described above.
Physical boundaries
Imposing physical boundaries (such as requiring \(\mu>0\) for a signal strength) is achieved by setting the ranges of the physics model parameters using
--setParameterRanges param1=param1_min,param1_max:param2=param2_min,param2_max ....
The boundary is imposed by restricting the parameter range(s) to those set by the user, in the fits. Note that this is a trick! The actual fitted value, as one of an ensemble of outcomes, can fall outside of the allowed region, while the boundary should be imposed on the physical parameter. The effect of restricting the parameter value in the fit is such that the test statistic is modified as follows ;
\(q(x) = - 2 \ln \mathcal{L}(x,\hat{\hat{\theta}}(x))/\mathcal{L}(\hat{x},\hat{\nu})\), if \(\hat{x}\) in contained in the bounded range
and,
\(q(x) = - 2 \ln \mathcal{L}(x,\hat{\hat{\nu}}(x))/\mathcal{L}(x_{B},\hat{\hat{\nu}}(x_{B}))\), if \(\hat{x}\) is outside of the bounded range. Here \(x_{B}\) and \(\hat{\hat{\nu}}(x_{B})\) are the values of \(x\) and \(\nu\) which maximise the likelihood excluding values outside of the bounded region for \(x\) - typically, \(x_{B}\) will be found at one of the boundaries which is imposed. For example, if the boundary \(x>0\) is imposed, you will typically expect \(x_{B}=0\), when \(\hat{x}\leq 0\), and \(x_{B}=\hat{x}\) otherewise.
This can sometimes be an issue as Minuit may not know if has successfully converged when the minimum lies outside of that range. If there is no upper/lower boundary, just set that value to something far from the region of interest.
Info
One can also imagine imposing the boundaries by first allowing Minuit to find the minimum in the unrestricted region and then setting the test statistic to that in the case that minimum lies outside the physical boundary. This would avoid potential issues of convergence. If you are interested in implementing this version in Combine, please contact the development team.
Extracting contours from results files
As in general for HybridNew, you can split the task into multiple tasks (grid and/or batch) and then merge the outputs with hadd. You can also refer to the combineTool for job submission section for submitting the jobs to the grid/batch or if you have more than one parameter of interest, see the instructions for running HybridNew on a grid of parameter points on the CombineHarvest - HybridNewGrid documentation.
Extracting 1D intervals
For one-dimensional models only, and if the parameter behaves like a cross section, the code is able to interpolate and determine the values of your parameter on the contour (just like it does for the limits). As with limits, read in the grid of points and extract 1D intervals using,
combine workspace.root -M HybridNew --LHCmode LHC-feldman-cousins --readHybridResults --grid=mergedfile.root --cl <1-alpha>
The output tree will contain the values of the POI that crosses the critical value (\(\alpha\)) - i.e, the boundaries of the confidence intervals.
You can produce a plot of the value of \(p_{x}\) vs the parameter of interest \(x\) by adding the option --plot <plotname>.
Extracting 2D contours
There is a tool for extracting 2D contours from the output of HybridNew located in test/makeFCcontour.py. This can be used provided the option --saveHybridResult was included when running HybridNew. It can be run with the usual Combine output files (or several of them) as input,
./test/makeFCcontour.py toysfile1.root toysfile2.root .... [options] -out outputfile.root
To extract 2D contours, the names of each parameter must be given --xvar poi_x --yvar poi_y. The output will be a ROOT file containing a 2D histogram of value of \(p_{x,y}\) for each point \((x,y)\) which can be used to draw 2D contours. There will also be a histogram containing the number of toys found for each point.
There are several options for reducing the running time, such as setting limits on the region of interest or the minimum number of toys required for a point to be included. Finally, adding the option --storeToys in this script will add histograms for each point to the output file of the test statistic distribution. This will increase the memory usage, as all of the toys will be kept in memory.